




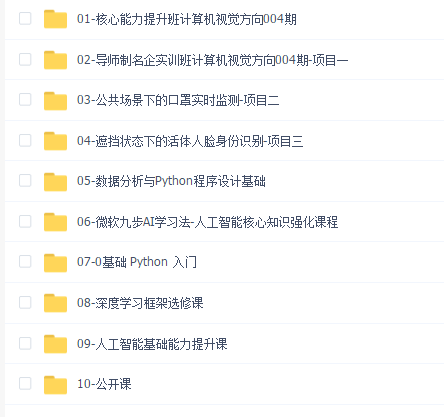
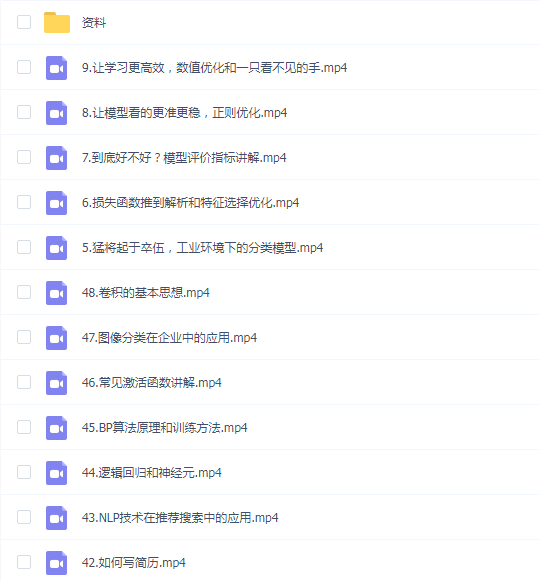
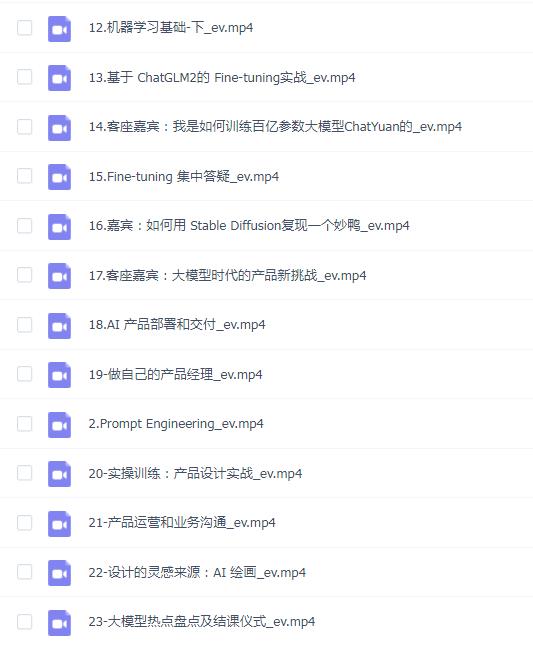
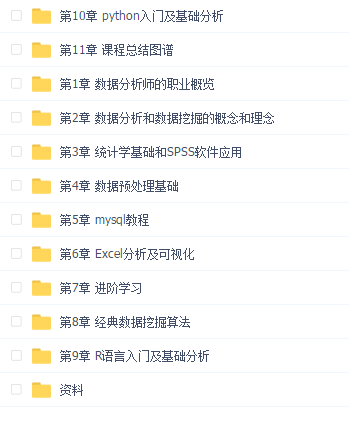

声明:本网站所有内容均为资源介绍学习参考,如有侵权请联系后删除


01开班典礼
开班典礼(6月30日 20:00-21:00)
02
hadoop-hdfs 存储、架构模型、角色、持久化
hadoop-hdfs 存储、架构模型、角色、持久化(7月1日 20:00-22:00)
03
hadoop-hdfs 读写流程、配置、完全分布式&CLI命令
读写流程配置完全分布式&CLI命令(7月3日 20:00-22:00)
04
hadoop-hdfs api开发 HA集群搭建
hadoop-hdfs api开发 HA集群搭建(7月5日 20:00-22:00)
05
hadoop-MR YARN架构理论与集群搭建、WordCount
hadoop-MR YARN架构理论与集群搭建(7月8日 20:00-22:00)
06
手写wordcount、hadoop-MR 开发&源码分析:客户端
手写wordcount、hadoop-MR 开发&源码分析(7月10日 20:00-22:00)
07
hadoop-MR源码分析:MapTask输入分析、MapTask输出分析
MapTask输入分析、MapTask输出分析(7月12日 20:00-22:00)
08
MR源码分析:Mapask输出分析、Reduceask输入分析
Mapask输出分析、Reduceask输入分析(7月15日 20:00-22:00)
09
MR源码分析:Reduceask输出分析及MR:天气案例
Reduceask输出分析及MR:天气案例(7月17日 20:00-22:00)
10
hadoop-MR开发案例:好友推荐案例及pagerank案例
MR:好友推荐案例及pagerank案例(7月22日 20:00-22:00)
11
hadoop-MR开发案例:tfidf案例及itemcf案例
hadoop-MR开发案例:tfidf案例及itemcf案例(7月24日 20:00-22:00)
12
Hive介绍以及安装
背景、架构、安装、内部表/外部表/分区表(7月29日 20:00-22:00)
13
Hive实战
案例等、动态分区/分桶、运行方式/调优(7月31日 20:00-22:00)
14
HBase介绍以及安装
数据模型、架构、搭建:伪分布式/全分布式(8月2日 20:00-22:00)
15
HBase调优
Hbase shell/ API、Mapreduce Hbase 整合(8月5日 20:00-22:00)
16
Hadoop项目需求分析
JS-SDK设计、Java-SDK设计、项目流程/架构(8月7日 20:00-22:00)
17
Hadoop项目准备
JS-SDK实现、Java-SDK实现、Nginx搭建(8月9日 20:00-22:00)
18
Hadoop项目数据采集以及清洗
Flume用法、日志收集的实现、ETL-数据清洗(8月12日 20:00-22:00)
19
Hadoop项目代码实现以及优化
mapreduce/Outputformat /mapreduce实现等(8月14日 20:00-22:00)
20
Hadoop项目架构扩展以及组件整合
Sqoop用法、Hive和hbase整合、hive分析等(8月16日 20:00-22:00)
21
storm理论-Storm介绍以及代码实战
IDE环境应用Storm及功能案例1(8月21日 20:00-22:00)
22
storm理论-Storm伪分布式搭建以及任务部署
Storm 伪分布式集群搭建(8月23日 20:00-22:00)
23
storm理论-Storm架构详解以及DRCP原理
Storm 全分布式集群搭建及任务部署(8月26日 20:00-22:00)
24
redis理论-redis类型
安装redis,数据类型:String、list、hash(8月28日 20:00-22:00)
25
redis理论-redis高级
持久化,主从复制,哨兵(9月2日 20:00-22:00)
26
Scala语法—Scala语法介绍
scala语言特点,scala开发环境的安装(9月4日 20:00-22:00)
27
Scala语法—scala语法实战
语法使用(9月6日 20:00-22:00)
28
Spark理论—介绍
Spark与MR对比、运行模式以及区别、RDD特性(9月9日 20:00-22:00)
29
Spark介绍、RDD的五大特性
Spark介绍、RDD的五大特性(9月13日 20:00-22:00)
30
RDD算子的讲解
RDD算子的讲解(9月16日 20:00-22:00)
31
RDD控制类算子以及集群搭建
RDD控制类算子以及集群搭建(9月18日 20:00-22:00)
32
SparkPi 计算圆周率的原理 以及高可用集群的搭建
SparkPi 计算圆周率的原理高可用集群的搭建(9月20日 20:00-22:00)
33
任务调度流程01
任务调度流程01(9月25日 20:00-22:00)
34
任务调度流程02
任务调度流程02(9月29日 20:00-22:00)
35
任务调度流程03
任务调度流程03(10月7日 20:00-22:00)
36
资源调度流程
资源调度流程(10月9日 20:00-22:00)
37
多种提交Application的方式以及 SparkShuffle
多种提交Application的方式 SparkShuffle(10月11日 20:00-22:00)
38
SparkShuffle
SparkShuffle(10月14日 20:00-22:00)
39
案例
案例(10月18日 20:00-22:00)
40
广播变量、累加器
广播变量、累加器(10月21日 20:00-22:00)
41
重分区算子
重分区算子(10月23日 20:00-22:00)
42
SparkSQL介绍
SparkSQL介绍(10月25日 20:00-22:00)
43
SparkSQL处理parquet json数据
SparkSQL处理parquet json数据(10月28日 20:00-22:00)
44
SparkSQL自定义函数 Spark on hive整合步骤
SparkSQL自定义函数 Spark on hive整合步骤(10月30日 20:00-22:00)
45
配置thrift server 安全机制 以及小区掉话率的统计案例
配置thrift server 安全机制(11月4日 20:00-22:00)
46
Spark调优(资源,并行度)
Spark调优(资源,并行度)(11月6日 20:00-22:00)
47
Spark调优(数据本地化调优)
Spark调优(数据本地化调优)(11月8日 20:00-22:00)
48
Spark解决数据倾斜的方案、SparkStreaming介绍
Spark解决数据倾斜的方案SparkStreaming(11月13日 20:00-22:00)
49
SparkStreaming案例
SparkStreaming案例(11月15日 20:00-22:00)
50
SparkStreaming on kafka
SparkStreaming on kafka(11月18日 20:00-22:00)
51
机器学习项目-推荐系统介绍以及架构分析
什么是推荐系统,以及推荐系统的前景(11月22日 20:00-22:00)
52
机器学习项目-推荐系统的特征工程
数据清洗,特征工程(11月24日 14:00-16:00)
53
机器学习项目-推荐系统代码实现以及部署
什么是dubbo为服务,代码实现,项目部署(11月25日 20:00-22:00)
54
Elasticsearch理论-Elasticsearch搜索原理
倒排索引与lucene框架原理(11月27日 20:00-22:00)
55
Elasticsearch理论-Elasticsearch实战
Elasticsearch集群搭建(11月29日 20:00-22:00)
56
大数据面试培训(一)
大数据面试培训(一)(12月4日 20:00-22:00)
57
大数据面试培训(二)
大数据面试培训(二)(12月6日 20:00-22:00)
58
机器学习
机器学习(12月11日 20:00-22:00)
59
ElasticSearch
ElasticSearch(12月13日 20:00-22:00)
60
机器学习
机器学习(12月16日 20:00-22:00)
61
机器学习
机器学习(12月18日 20:00-22:00)
62
机器学习
机器学习(12月23日 20:00-22:00)
63
机器学习
机器学习(12月25日 20:00-22:00)
64
机器学习
机器学习(1月3日 20:00-22:00)
65
机器学习
机器学习(1月6日 20:00-22:00)
66
机器学习
机器学习(1月8日 20:00-22:00)
67
机器学习
机器学习(1月10日 20:00-22:00)